PROYECTO DE INVESTIGACION
| NOMBRE Y APELLIDO | Carlos López Vázquez |
| CÉDULA DE IDENTIDAD | 1.555.799-3 |
| NO. DE FUNCIONARIO | 26632 |
| CARGO Y DEDICACIÓN HORARIA | Prof. Agregado, 40 hs. |
| SERVICIO UNIVERSITARIO Y REPARTICIÓN | Facultad de Ingeniería, Centro de Cálculo |
| DIRECCIÓN (*) | J. Herrera y Reissig 565 |
| TELÉFONO (*) | 714229 |
| FAX (*) | 715446 |
| EMAIL (*) | carlos.lopez@ieee.org |
(*)Del Servicio y repartición donde se realizará el proyecto.
| TITULO DEL PROYECTO
|
Despacho mejorado de Cálculo Cíentifico Distribuido en redes de computadoras no dedicadas usando PVM |
| DURACIÓN TOTAL DE LA INVESTIGACIÓN (MESES) | 18 meses |
| TIPO DE INVESTIGACIÓN | INICIACIÓN
INVESTIGACION Y DESARROLLO x |
| OTROS FONDOS | ||
| 1er. AÑO | U$S 10.000 | |
| 2do. AÑO | U$S 5.000 | |
| TOTAL | U$S 15.000 |
AREA EXACTAS Y NATURALES
AREA TECNOLOGICAS
Subdisciplina 1ª:___Computación científica__________
| SI | X |
| NO |
7) SI EL PLAN O PROGRAMA GENERAL O UN PROYECTO
EN ESE MARCO DIFERENTE AL
PRESENTADO A LA C.S.I.C., YA CUENTA CON FINANCIACION,
AGREGUE LA INFORMACION
SOLICITADA.
| FUENTE | MONTO (U$S) | PERIODO | TITULO DEL PROYECTO O PROGRAMA |
| Union Europea-ITDC(Information Technologies for Developing Countries) program | 120.000 | 1995-1998 | PERFORMANCE OF A SHALLOW WATER MODEL AND A GLOBAL
CLIMATE MODEL DISTRIBUTED ACROSS HOMOGENEOUS AND HETEROGENEOUS PARALLEL
ARCHITECTURES UNDER IMPROVED PVM DISPATCH
|
| C.S.I.C | NOMBRE DEL PROYECTO |
| 1991
SI NO x
1992 SI NO x 1994 SI NO x |
| SI | x |
| NO |
ESPECIFIQUE:
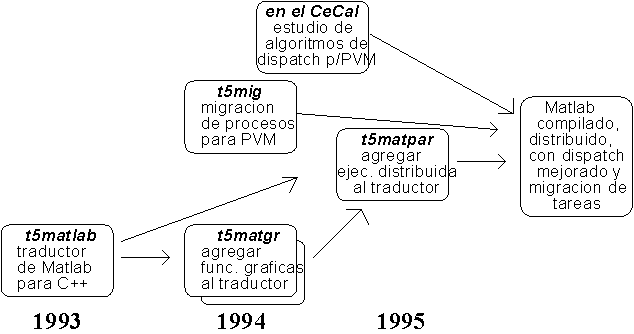
El proyecto está enmarcado en las actividades y acciones necesarias
para mantener, mejorar e incrementar la capacidad de cálculo científico
del CeCal. Los trabajos tienen objetivos múltiples y algunos implican
varias etapas, algunas de las cuales ya han sido cumplidas con trabajos
de grado de estudiantes de la carrera de Ingeniería en Computación.
En concreto se han desarrollado trabajos para mejorar las prestaciones
de códigos generados en lenguaje Matlab (proyectos t5matlab y t5matgr);
para obtener en forma semiautomática código paralelo capaz
de ser utilizado en las instalaciones actuales operando bajo el ambiente
PVM (proyecto t5matpar); desarrollo de una facilidad acoplable al PVM capaz
de retirar (migrar) un proceso de una máquina que durante
el cálculo y por razones ajenas a él se ha cargado en forma
desmedida y reiniciarlo en otra máquina menos cargada sin pérdida
de los resultados intermedios (proyecto t5mig).
La presente etapa (para el cual se plantea contratar un estudiante que
pueda hacer su proyecto de fin de carrera) se conectará en forma
transparente con las anteriores. No requiere ni está vinculada obligatoriamente
a los proyectos asociados al Matlab; en particular, el ejemplo sugerido
para evaluar los resultados ha sido programado en FORTRAN, y se espera
que sea recibido con interés por la comunidad de usuarios de PVM.
La figura 1 ilustra las relaciones entre los proyectos mencionados.
10) INCORPORA ESTE PROYECTO TRABAJOS DE POSGRADO:
| SI | x |
| NO |
ESPECIFIQUE:
El Ing. Elías Kaplan está
completando sus actividades de Maestría e iniciando el Doctorado
con la paralelización del código relativo al Río de
la Plata.
11) RESUMEN DE LA INVESTIGACIÓN: (UTILICE 1 CARILLA)
El proyecto que se propone es parte de una estrategia de desarrollo para
disponer en la Facultad de un sistema capaz de atender las necesidades
de cálculo intensivo de las aplicaciones de ingeniería que
el medio demanda. Así por ejemplo, el cálculo de la evolución
de una mancha de petróleo en el Rio de la Plata o la simulación
del clima en el Uruguay son tareas que demandan fuertemente a las computadoras
utilizadas.
La solución más simple sería el uso de un supercomputador.
Esta alternativa puede descartarse por su alto costo, etc. La segunda alternativa
sería utilizar las técnicas de cálculo distribuído
entre varias computadoras tipo estaciones de trabajo (ET) exclusivamente
dedicadas a tal fin. En este caso se pueden utilizar softwares apropiados
para lograr performances comparables a la de la supercomputadora. Esta
alternativa también es sin embargo inviable en nuestro medio, por
lo que lo único posible con un costo razonable es utilizar una red
de ET no exclusivamente dedicadas, compartiendo así su uso
con otras aplicaciones. Esta alternativa mejora sustancialmente la relación
costo/beneficio del equipamiento, al no requerir una dedicación
exclusiva del mismo al cálculo.
Esta realidad no es sin embargo corriente en los países desarrollados,
donde tanto la primera como la segunda alternativa son moneda corriente.
Es por ello que los softwares desarrollados para manejar redes de ET prestan
poca atención al problema de la carga futura de la máquina.
Simplemente despachan las tareas a medida que se les solicita asignándoselas
a las CPUs que no están siendo ocupadas (en el caso de las redes
dedicadas) o a la menos cargada instantáneamente (en el caso de
redes de uso compartido).
El problema que intenta resolver este proyecto es lograr un buen balance
de cargas de una red de ET, a través del mejor gerenciamiento del
despacho de tareas.
Este mejoramiento se logrará estudiando los patrones de carga de
las computadoras componentes de la red considerada, tratando de predecir
su comportamiento futuro y, en base a ello, tomar una decisión óptima
en el despacho de tareas (con un horizonte del orden de minutos). Cada
vez que una aplicación distribuída tiene que lanzar la ejecución
de un proceso a la red, no deberá solamente tener en cuenta la carga
instantánea de las computadoras interconectadas, sino que también
la información de carga típica de los componentes de la red.
Para y previo a ello, se obtendrá información histórica
de la red, a la que se le intentará ajustar modelos, hasta llegar
a un modelo predictor satisfactorio. Esto ya se ha hecho con series temporales
de tipo meteorológico en uno de los proyectos del CeCal citado como
antecedentes (López, 1997) . Este es en sí mismo uno de los
principales objetivos.
Los mecanismos de despacho de tareas nuevos, serán integrados al
sistema PVM (Parallel Virtual Machine) (Geist, 1993; Dongarra 1993), que
es uno de los más usados para programar aplicaciones distribuídas
en una red de computadoras. La integración de estos nuevos algoritmos
de despacho será transparente para los usuarios que ya tengan aplicaciones
PVM en funcionamiento.
Finalmente, para probar la bondad de los nuevos algoritmos considerados,
se deberán confrontar con los actualmente en uso, bajo las mismas
condiciones. Esto significa que se deberá implementar un experimento
que
permita correr programas distribuídos bajo condiciones de carga
prefijadas (o sea, no libradas al azar), pero usando distintos criterios
de predicción de carga a futuro.
Lograr este ambiente no es un problema menor y es otro de los objetivos
del proyecto. Para ello, se dispone de una serie histórica de la
carga de las computadoras de la red en estudio, y datos fehacientes de
su potencia relativa. Se deberán implementar programas que permitan
lograr reproducir la stuación de carga de esas computadoras en forma
lo más " coherente " posible con la información histórica
disponible puesto que es necesario llegar a repetir el experimento de lanzar
un mismo programa a un mismo estado de carga de la red, con distintos criterios
de predicción.
El desempeño del sistema en su conjunto se evaluará utilizando
programas de cálculo científico actualmente operativos en
el CeCal, relacionados con aplicaciones reales de interés para el
Uruguay. En particular se empleará el programa PTIDAL para
el cálculo de corrientes de marea desarrollado en el CeCal (Kaplan,
96). A modo de ejemplo para analizar el comportamiento de una mancha de
petróleo (como la del accidente del buque San Jorge ocurrido recientemente)
es necesario simular una semana de corrientes y del transporte del contaminante.
Dicho cálculo realizado en forma serial (operando en una única
ET potente y dedicada) emplearía 4,5 días, lo cual
resulta inaceptable. Para decidir las medidas a tomar que contrarresten
los efectos catastróficos del accidente los plazos son mucho más
exigentes.
En cambio el programa distribuído empleando 4 ET (también
dedicadas exclusivamente) simula dicho comportamiento en sólo 1,2
días, lo cual sería aceptable si fuera posible
disponer dicho equipamiento en forma exclusiva. El problema surge al realizar
la simulación en forma distribuida con las ET no dedicadas exclusivamente
a este cálculo lo que ocasiona un incremento del tiempo de cálculo
que puede a llegar a superar el tiempo serial en función
de cómo se seleccionan las ET a emplear. La meta del presente proyecto
es la de optimizar el uso de las ET de forma de poder realizar el cálculo
antedicho minimizando el tiempo de cálculo.
11.1) Detalles de la Investigación
(no mas de 18 carillas)
A.- FUNDAMENTACION Y ANTECEDENTES
Desde los comienzos de la era de las computadoras, el requerimiento de
mayor poder de cálculo ha sido una constante. La Facultad de Ingeniería
no ha sido ajena a esa tendencia, siendo en el área hidrodinámica
un buen ejemplo de ello. Actualmente se está dando en el mundo una
preeminencia cada vez mayor de los modelos numéricos sustituyendo
donde es posible a los modelos físicos.
Por ello, y debido a la creciente magnitud de los problemas encarados (modelación
tridimensional, mallas con miles de puntos, mayor orden de las soluciones,
modelación de los fenómenos turbulentos, salidas gráficas
en tiempo real) la capacidad computacional requerida en flops se ha incrementado.
Para satisfacerla, además de mejorar los procesadores, se desarrolló
una tecnología basada en el uso simultáneo de más
de un procesador, esquema conceptual adaptable en buena parte a la mayoría
de las aplicaciones.
Así, la paralelización de programas de fluido-dinámica
ha venido realizándose en ambientes científicos y técnicos
empleando supercomputadoras con varios procesadores (Davies, 1990) o redes
de computadoras del tipo estaciones de trabajo (ET en lo que sigue) conectadas
en red y pasándose mensajes entre los programas (Bergman, 1993;
Dongarra, 1993; Kaplan, 1996).
Para maximizar el rendimiento de una red formada por ETs interconectadas,
se hace necesario estudiar las características de uso de cada una
de las componentes de la red, de forma de poder explotar los tiempos muertos
de unas, para dejar más libres a las otras (Mutka, 1992). Así
se lograría un buen balance de la red, que es el objetivo final
del proyecto.
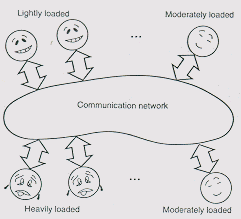
Figura 2.- Sistema Distribuído sin Balance de Carga
B.- OBJETIVOS GENERALES Y ESPECÍFICOS
Generales:
· Implementar una mejora en los
sistemas de gestión de la máquina virtual paralela actualmente
operativa en la Facultad de Ingeniería
· Ensayar tal mejora y evaluar
objetivamente los resultados obtenidos
· Elaborar modelos estadísticos
para predecir la operación futura de la red a corto plazo
· Demostrar la posibilidad de dar
respuesta a las demandas de cálculo en apoyo a los potenciales demandantes,
ilustrándose con el caso de organismos estatales responsables de
la gestión ambiental y física de la zona costera y plataforma
marítima.
Específicos
· Desarrollar y validar un modelo
de Predicción de Carga de cada una de las componentes de una red
de ET no dedicadas, usando información histórica y estadística
disponible.
· Elaborar criterios de despacho
de tareas en un ambiente de computación distribuída, de forma
de optimizar el balance de cargas de la red.
· Generar un software capaz de
replicar en la red una serie temporal de estados de carga de ETs individuales.
· Evaluar como ejemplo la mejora
en la performance de un modelo numérico para la simulación
hidrodinámica de las corrientes de marea astronómica y de
viento en el Río de la Plata capaz de ser utilizado en áreas
de interés con gran definición (orden de 100 metros de tamaño
de grilla)
C- ESPECIFICACIÓN DE LAS PREGUNTAS QUE BUSCA RESPONDER EL PROYECTO
¿ Qué criterio de despacho
de tareas se puede aplicar en una red especifica de ET no dedicadas para
minimizar los tiempos de ejecución de un programa de cálculo
científico dado ?
¿ Qué modelo matemático
es más preciso para predecir la carga de trabajo de una ET particular,
en un horizonte de minutos ?
¿ Puede decirse que el criterio de despacho A es mejor que el B ?
¿ Como se pueden unir las respuestas a las preguntas anteriores en una instalación concreta, y poniéndolas bajo la forma de una rutina de despacho, invisible además al usuario ?
Suponiendo que todo lo anterior se logre, ¿ A cuánto asciende la ventaja en términos de tiempo (también demoninada speed-up) en una aplicación concreta ?
D.- ESTRATEGIA DE INVESTIGACIÓN
Se atacarán cuatro problemas simultánea e independientemente tal como se describe en las actividades específicas.
Con los puntos anteriores cumplidos,
se realizará un ensayo comparativo de los diferentes métodos
de despacho propuestos, y se evaluarán los resultados en términos
del tiempo requerido de cálculo, utilizando como problema test un
modelo numérico existente escrito en FORTRAN .
Replicación en una ET dada de un estado de carga
Para probar la bondad de los nuevos algoritmos que se desarrollarán
para mejorar el despacho de tareas en un ambiente de computación
distribuída utilizando información estadística sobre
el uso de las computadoras involucradas, será necesario ejecutar
varias veces el mismo programa distribuído, usando en cada corrida
un algoritmo diferente de despacho de tareas. Sin embargo, para que la
comparación sea realmente justa, dichas corridas deberán
ejecutarse sobre las mismas condiciones de carga de la red.
Por ejemplo, si deseamos comparar los algoritmos A y B de despacho de tareas,
y usamos como programa de prueba el programa distribuído P, sería
injusto correr el programa P con el despachador de tareas A a las doce
del mediodía (cuando hay muchos usuarios trabajando, y la red esta
cargada) y correr el programa P con el despachador de tareas B a las doce
de la noche ( cuando probablemente no haya nadie trabajando en la red );
en esta comparación ( ignorando el ambiente de trabajo ), casi seguro
que el algoritmo B se muestre mejor, cuando en realidad A es mejor.
Siguiendo con el ejemplo anterior, tampoco es una solución fiel
evaluar el algoritmo A a las doce del mediodía de hoy, y el algoritmo
B a las doce del mediodía de otro día, dado que el hecho
de que sea la misma hora no implica que la red tenga la misma carga.
O sea, lo que se necesita es poder recrear el mismo ambiente de trabajo,
para que un mismo programa distribuído pueda ser ejecutado varias
veces bajo las mismas condiciones ( cambiando solamente el algoritmo de
despacho de tareas a usar ); ello se logra si se puede lograr cargar artificialmente
cada una de las computadoras de la red de forma que se aproxime lo más
posible a la carga que tuvo en algún período de tiempo. Esta
replicación deberá poder ser adaptativa, en el sentido de
que se ajuste a la situación en que se encuentre la red en ese momento;
o sea, si tenemos que lograr carga X y en el momento de la replicación
la computadora tiene carga Y, entonces se deberá crear una carga
de X-Y en la computadora, de forma de alcanzar el objetivo.
Modelos de Predicción
a) Tradicionales (Series Cronológicas)
Uno de los principios básicos de la predicción estadística
es que el predictor debería usar el comportamiento de los datos
en el pasado, de modo de obtener una lectura de carga y una estimación
de la velocidad con que esa carga crece o decrece.
El problema no es tan sencillo como parece, sin embargo. Generalmente es
difícil hacer proyecciones de datos en bruto, dado que velocidades
y tendencias no son inmediatamente detectables. En general se hallan mezcladas
con variaciones estacionales y/o son distorsionadas por varios factores
como caídas de tensión, por ejemplo.
Existen varios parámetros que permiten medir qué tan cargada
está una computadora: por ejemplo, a cuántos usuarios está
atendiendo al mismo tiempo, porcentaje del tiempo real y qué porcentaje
del tiempo está simplemente esperando que alguien "teclee" algo,
etc. Bajando un poco más de nivel, y yendo a medidas provistas por
el kernel del sistema operativo, nos encontramos con valores más
finos como: paquetes de red enviados y/o recibidos por segundo, actividad
de paginado y swapeado por segundo, tráfico de disco en transferencias
por segundo, cantidad promedio ( últimos 5, 10 y 15 minutos ) de
procesos en condiciones de ser ejecutados, la cantidad de memoria disponible,
etc.
Determinar cuál, cuáles o si alguna combinación de
cuáles de todas ellas es lo más representativo de la carga
real de la computadora, es un tema bastante subjetivo. Sin embargo, los
investigadores han detectado empíricamente que el más efectivo
de todos ellos parece ser el promedio de procesos en condiciones de ser
ejecutados (variable load). (Shivaratri et al., 1992; Kunz,
1991 )
Desde un punto de vista práctico, sin embargo, los parámetros
que miden el uso de CPU, disco y red (cpu, pck y dsk) que está
teniendo la máquina, no deberían ser ignorados. Por ejemplo,
si una computadora tiene sólo un proceso corriendo, pero dicho proceso
utiliza mucha memoria y toda la CPU disponible, entonces el índice
mencionado anteriormente no se vería mayormente afectado, si bien
la máquina estaría realmente cargada.
Los datos en bruto deberán ser procesados antes de ser usados en
la modelización, y esto, frecuentemente es realizado por medio del
análisis de Series Temporales.
Una Serie Temporal es un conjunto de datos cronológicamente ordenados.
En este caso, los datos que se tendrán en cuenta, corresponden a
cuatro de las variables del sistema, a saber: uso de cpu, uso de red,
uso de disco y carga del sistema.
Por medio de técnicas de análisis de Series Temporales se
intentará identificar y explicar:
- toda regularidad o variación sistemática en la carga debida
a estacionalidades
- patrones cíclicos que se repitan semanalmente, mensualmente, etc.
- tendencia en los datos
- variaciones de tendencias
El análisis de la serie temporal se hará en forma individual
para cada componente de la red, dejando de lado, en esta primer aproximación
al tema, el problema de las correlaciones que puedan existir entre las
medidas de cada una de las estaciones terminales de la red ( la predicción
de carga no es encarada para la red global, sino para cada una de sus partes
).
El trabajo se enfocará por dos vías, que serán la
base de los algoritmos de despacho de tareas que se confrontarán
luego. Se considerará:
a) la variable load
b) un "bloque" de variables: cpu, pck, dsk
La metodología a aplicar a a), se basará en los modelos ARMA,
ARIMA, (Wei, 1989; Brockwell et al., 1991), y, en caso de detectarse
que no hay homogeneidad de varianza (Brewsch et al., 1979), los
modelos ARCH (Novales et al., 1991; Engle, 1972; Engle, 1975).
En lo que se refiere a b), se hará un estudio previo para detectar
una posible relación funcional entre las tres componentes del "bloque",
y, de este modo, poder utilizar las metodologías descritas para
el caso anterior. De no encontrarse dicha vinculación, se encarará
el problema vectorialmente, hasta el grado de complejidad que se justifique
en este primer acercamiento al tema.
b) No tradicionales (redes neuronales artificiales)
Los métodos lineales descritos han sido usados con éxito
en un gran número de aplicaciones, en los que se enfatiza en la
predicción a corto plazo. En nuestro caso, interesa una predicción
apropiada también en el mediano y largo plazo, para lo cual se propone
considerar como alternativa las redes neuronales artificiales (ANN en lo
que sigue).
El problema de elegir el "mejor" método de predicción no
es nuevo. Ya trabajos como los de Makridakis et al (1982) o Makridakis
et
al. (1993) lo han intentado y desafortunadamente la conclusión
es que no hay un método que sea universalmente optimo para cualquier
serie. En particular, el trabajo de Makridakis et al (1982) también
denominada ¨Competencia M¨ comparó 24 métodos con
1001 series de datos diferentes, llegando a la conclusión que la
ventaja de los métodos de Box y Jenkins (1970) (B&J en lo que
sigue) para series univariadas que resultaba de los experimentos previos
no era tal. Por cierto que esta en curso el experimento M3, que analizara
3003 series diferentes (Anon, 1997).
Por otra parte, algunos métodos mas modernos surgidos con posterioridad
fueron contrastados con éxito con la misma base de datos. Así,
Sharda and Patil (1990) compararon el desempeño de ANN con los métodos
de Box y Jenkins en 75 de los casos de la Competencia M, llegando a la
conclusión que las primeras pueden mejorar significativamente el
desempeño de las últimas en algunos casos. Similares resultados
fueron obtenidos por Chang y Fishwick (1991). En los experimentos realizados
pudieron verificar que incluso en varios de los casos en que Sharda y Patil
(1990) declaraban que las ANN tenían un resultado comparable a B&J
las redes no habían sido suficientemente entrenadas, o los parámetros
no habían sido convenientemente elegidos. Ellos mostraron que las
ANN podían rendir mejores resultados que los informados, pero que
ello requería un análisis mas detallado de los datos.
Este resultado no es sorprendente. En los últimos 10 años
(a partir del trabajo de Rumhelhart et al., 1986) se ha avanzado
mucho en el tema, y la técnica se ha aplicado con éxito en
muchísmos más casos que los cubiertos por la Competencia
M. Sólo a modo de ejemplo pueden citarse: estudio de la demanda
en redes eléctricas (Islam et al., 1995; Srinivasam et
al., 1995; Miyake et al., 1995), de contaminantes en la atmósfera
(Boznar et al., 1993), toma de decisiones (Márquez et
al., 1994) y recientemente por parte de nuestro equipo en el tema de
series temporales de lluvia diaria (López, 1997).
Chang y Fishwick (1991) también observaron que las ANN tenían
un mejor desempeño cuando se las utilizaba para extrapolar directamente
12 meses a partir de los 12 anteriores, en lugar de aplicar 12 veces una
extrapolación de un mes (como requiere B&J o como podría
hacerse también con ANN). Ello tiene implicancias inmediatas para
un problema como el nuestro, ya que fijado el horizonte de la predicción,
lo que interesa es minimizar el error conjunto y no necesariamente hacer
una predicción óptima para los primeros instantes en desmedro
de los posteriores.
Al igual que en el caso de los métodos tradicionales, para la aplicación
de las ANN se visualizan dos etapas. La primera consistirá en evaluar
la posibilidad de producir estimaciones razonables basándose únicamente
en la historia de la CPU particular en la que se requiere la predicción.
Este enfoque univariado parece imprescindible, porque podría ocurrir
que la misma diera resultados razonables, evitándose por tanto la
complejidad de las redes multivariadas (que tienen muchisimos mas parámetros
a entrenar). Este será un objetivo a cumplir.
La segunda etapa intentará realizar la predicción basándose
en la información temporal de la CPU dada, y de las demás
de la red. Para el entrenamiento se espera que solo un numero limitado
de muestras sea suficiente, lo que permitiría manejar eficientemente
eventuales cambios en la red (aparición de una nueva máquina,
salida de servicio de otras, etc.). Cualquier cambio debería requerir
un período de entrenamiento (necesariamente breve) para la ANN.
G.-CRONOGRAMA DE EJECUCIÓN
H.- DESCRIPCIÓN DETALLADA DE LAS TAREAS QUE REALIZARAN LOS INTEGRANTES DEL EQUIPO (INCLUIR PERSONAL DOCENTE Y NO DOCENTE EXISTENTE, EXTENSIONES DE CARGOS DOCENTES Y NO DOCENTES, NUEVOS CARGOS DOCENTES).
CARLOS LÓPEZ: Grado 4, 50% de 40hs. semanales
I.- RESULTADOS ESPERADOS
J.-ESTRATEGIAS DE DIFUSIÓNBuena parte de la difusión se realizará mediante intercambio via e-mail y grupos de interés. Sin perjuicio de ello se asistirá a congresos, y se planea poner bajo dominio público el software resultante.
K.-IMPACTO Y/O BENEFICIOS DE LOS RESULTADOS
Las necesidades de potencia de cálculo están fundamentalmente asociadas a la investigación realizada por los institutos de la facultad y/o los convenios en que la misma se involucra. El Centro de Cálculo ha sido en el pasado el proveedor casi exclusivo de potencia de cálculo, situación que ha evolucionado junto con la tecnología y el crecimiento de la red de facultad. En este momento sólo las aplicaciones de cálculo muy intensivo (a las cuales apunta este proyecto) se beneficiarían directamente con sus resultados.
La reducción de inversiones asociada a un mejor uso de los recursos informáticos inactivos puede ser considerable, especialmente ante demandas de cálculo intensivo. Una super-mini-computadora tiene costos de adquisición que son múltiplos de los costos de las ET en uso en el proyecto, y tiene además otros inconvenientes, como ser la dificultad de su mantenimiento (porque en el mundo se fabrican pocas unidades del mismo modelo) y su uso exclusivo para aplicaciones de cálculo. La red de ET permite un uso más flexible, facilitando además un escalonamiento de las inversiones, como se ha hecho en la facultad.L.-REFERENCIAS BIBLIOGRÁFICAS
11.2) CONFIGURACIÓN DEL GRUPO DE INVESTIGACIÓN
A.- INTEGRANTES DEL GRUPO (INCLUIR TESISTAS)
M.Sc. Carlos López, Ing. Elías Kaplan, Ing. Antonio López y Lic. Celina Gutierrez
B.- INSTITUTO, SERVICIO O LABORATORIO
Centro de Cálculo, Facultad de Ingeniería
C.- PROYECTOS EN EJECUCIÓN, ORGANISMOS QUE LO FINANCIAN
Se encuentran en este momento 4 proyectos en vias de ejecución directamente vinculados con esta propuestaC.1.- Proyecto MNCD
"Modelo Numérico de Corrientes de Marea y Viento para uso distribuido en una red de estaciones de trabajo" (MNCD) y calibración de dicho modelo en el Río de la Plata y su plataforma continental.
Monto y financiamiento : CONICYT-BID 87/94 69.000 U$S
Universidad de la República: 34.000 U$S
Total: 103.000 U$SLa modelación numérica de fenómenos físicos, en particular en la mecánica de los fluidos, esta teniendo gran difusión como complemento o reemplazo de la modelación física.
Debido a la creciente magnitud de los problemas encarados (mallas con miles de puntos, mayor orden de las soluciones, modelación de los fenómenos turbulentos, salidas gráficas en tiempo real) la capacidad computacional requerida, medida en flops (operaciones de punto flotante por segundo), se ha incrementado. Ello ha llevado a enfrentar dichos problemas con el uso de varias computadoras conectadas en red, integrándolas en paralelo como una "maquina virtual" mediante pasaje de mensajes a través de la red. La introducción de la tecnología de paralelización del modelo numérico permite obtener los resultados en tiempo real. Es posible operarlo también con un modelo de transporte y dispersión de escalares (contaminantes, particulas en suspensión, larvas, derrames petroliferos, etc)
Para paises como el Uruguay es una alternativa económicamente más viable, y de mayor aprovechamiento para los organismos, que la de disponer de una supercomputadora capaz de resolver los problemas antes mencionados por si solo. Permite utilizar la red de computadoras existente, en el caso del CeCal, ya se cuenta con una red de 5 estaciones a las cuales se suman las de la Facultad de Ingeniería totalizando unas decenas. Dichas computadoras pueden funcionar individualmente como estaciones gráficas o para cálculos menos intensos y utilizando su capacidad "sumada", posiblemente en horas de bajo requerimiento por los usuarios particulares, para la resolución de los problemas que se encaran.C.2.- Proyecto "URU-Parallel" - ITDC 194
Performance of a Shallow Water Model and a Global Climate Model distributed across homogeneous and heterogeneous parallel architectures.
Monto y financiamiento : Union Europea - ITDC 194 156.000 U$S
Universidad de la República: 80.000 U$S
Total: 233.000 U$SLa propuesta "URU-Parallel" fue presentada a la Union Europea en el marco del llamado ITDC'94 ("Information Technologies in Developing Countries") recibiéndose en Julio de 1995 el equipamiento solicitado, constituido por:
C.3.- Proyecto Centro de Cálculo-Royal Institute of Technology (Estocolmo)3 estaciones de trabajo de altas prestaciones equipadas con disco SCSI, CD-ROM, unidad de cinta de alta capacidad, conexión a red FDII de 100 mbit por segundo 1 estación de trabajo de altas prestaciones del tipo multiprocesador SMP (Shared Memory Processors) con 4 procesadores, equipadas con disco SCSI, CD-ROM, unidad de cinta de alta capacidad, conexión a red FDII de 100 mbit por segundo Router con interfaces: a.- WAN para conexión a Internet a 64 kb/s o más, b.- LAN ethernet para conexión a la red de facultad de ingeniería (fing.edu.uy), c.- LAN FDDI para conexión a las estaciones de trabajo de la nueva red de fibra óptica (red fddi.fing.edu.uy) Software: sistemas operativos, compiladores, utilitarios.
Monto y financiamiento : Colaboración Sueca(BITS) 1:400.000 U$S
Total: 1:400.000 U$SLa formación de personal del CeCal se viene llevando a cabo mediante dos acuerdos de colaboración con el el Intituto Suecto de Ayuda (BITS) que financian la llegada de docentes suecos para dictar cursos de Computación Cirntífica, Paralelismo, Fluido Dinámica Computacional, SIG, etc. También se financian las pasantías de investigación de los docentes del CeCal en el Royal Institute of Technology de Estocolmo, Suecia. En este marco el personal científico que intervendra en el proyecto se ha formado en los temas relativos al mismo.
A esto debe agregarse las becas de doctorado y maestría financiadas también por el CONICYT-BID en las que participan 2 de los científicos del proyecto y otros integrantes del CeCal.C.4.- Proyecto de control de calidad de datos meteorológicos e imputación de valores ausentes
Monto y financiamiento : CONICYT-BID 51/94 241.000 U$S
Universidad de la República: 85.000 U$S
Total: 326.000 U$SEl proyecto tiene como objetivo el estudio de diferentes técnicas aplicables fundamentalmente (pero no en forma excluyente) a datos meteorológicos, para resolver los problemas principales que se detallan a continuación:
a) detectar errores aleatorios en un banco de datos existente
b) señalar valores sospechosos en el momento de su ingreso al banco de datos
c) imputar o asignar valores para los datos ausentes, tanto en tiempo real como en el propio banco
(entendiéndose como tiempo real, la ejecución de las tareas mencionadas en lapsos comparables
con el insumido en el ingreso de la información).
a) un sistema de detección de errores
e imputación de valores ausentes que comprenda una colección
de algoritmos
aplicables a diferentes
parámetros. Tales algoritmos serán ensayados no sólo
con parámetros hidrometeorológicos
sino también
con otros de diferente origen.
b) tres bancos de datos depurados exhaustivamente,
con una estimación del nivel de errores remanente. Las variables
a
considerar serán
la precipitación diaria, el viento horario (de superficie) y el
nivel en el Río Tacuarembó
c) tres bancos de datos imputados, con
estimación del error probable cometido.
d) un sistema informático de base
de datos diseñado para operar, mantener y acceder grandes masas
de datos
meteorológicos
con lenguajes estándares tipo SQL, con información de calidad
a nivel de dato individual. Este istema
ya está operativo
para información tabular (2D+tiempo)
D.- PROYECTOS EJECUTADOS EN LOS ÚLTIMOS 5 AÑOS
Sólo se mecionan los proyectos más directamente relacionados al tema del presente proyecto ejecutados por integrantes del equipo científico.
D.1.- Proyecto Centro de Cálculo
Monto y financiamiento :
CONICYT-BID 180/92
100.000 U$S
Total:
100.000 U$S
El proyecto CONICYT-BID 180/92 tuvo como finalidad el equipamiento computacional
del Centro de Cálculo con la adquisición de 8 estaciones
de trabajo de mediano y gran porte y sus periféricos. Permitió
potenciar la capacidad de cálculo disponible y mejorar la red de
computadoras de Ingeniería.
Se complementó con la formación de personal mediante dos
acuerdos de colaboración con el el Intituto Suecto de Ayuda (BITS)
que financio la llegada docentes suecos para dictar cursos de Computación
Científica, Paralelismo, Fluido Dinámica Computacional, etc.
También permitió efectuar varias pasantías de investigación
en el Royal Institute of Technology de Estocolmo, Suecia a el personal
científico que intervendrá en el proyecto.
A esto debe agregarse las becas de doctorado y maestría financiadas
también por el CONICYT-BID en las que participan 2 de los cientificos
del proyecto y otros integrantes del CeCal.
E.- VINCULOS DEL GRUPO CON OTRAS UNIVERSIDADES Y/O CENTROS ACADEMICOS
Existe un acuerdo de Cooperación con el Royal Institute of Technology de Estocolmo (Suecia) para el intercambio de investigadores y docentes. Este acuerdo comenzó en 1991 y se renovó en 1995, estando prevista su finalización en 1998. En particular el acuerdo incluye al grupo del PDC (Parallell Data Center) que es el centro nacional sueco para el cálculo científico. Investigadores del mismo han visitado el CeCal en repetidas ocasiones, y docentes uruguayos han tenido varias estadías de dos meses c/u en sus instalaciones. El Ing. Kaplan está realizando su maestría supervisado por profesores suecos de ese laboratorio.
F.- PUBLICACIONES DEL GRUPO EN LOS ULTIMOS 5 AÑOS
PUBLICACIONES
ARTICULOS: REVISTAS ARBITRADAS
Locating random errors
in digital terrain models (1996).Carlos López To appear in International
Journal of Geographic Information Systems
Análisis por
componentes principales de datos pluviomitricos. a) Aplicación a
la detección de datos anómalos (1994) Carlos López,
Jorge Goyret Elizabeth González ESTADÍSTICA, 46, 146,147,
25-54.
Análisis por
componentes principales de datos pluviomitricos. b) Aplicación a
la eliminación de ausencias (1994) Carlos López, Juan F.
González y Rosario Curbelo ESTADÍSTICA, 46, 146, 147,
55-83.
Aplicación de
un modelo de corrientes en diferencias finitas al Río de la Plata
(1992) Rafael Guarga; Elías Kaplan; Susana Vinzón; Hugo Rodríguez;
Ismael Piedra Cueva. Revista Latinoamericana de Hidráulica. San
Pablo, Brasil
ARTICULOS: REVISTAS NO ARBITRADAS
Sistema THUEDA (Transmisión de Huellas dactilares) Andrés Almansa, Olaf Bergengruen, Rosario Curbelo & Gustavo Drets (1993) Revista Integrando - Facultad de Ingeniería
CONGRESOS ARBITRADOS
CONGRESOS NO ARBITRADOS
REPORTES TECNICOS
Los reportes técnicos producidos en el CeCal que no incluyen las publicaciones anteriores son:
El proyecto se desarrollará en el Centro de Cálculo, Facultad
de Ingeniería, donde está instalada la red de computadoras
conectadas a alta velocidad medinate fibra óptica, adquiridas en
el marco del proyecto ITDC de la Union Europea.
El área de oficinas disponible es de 100 m2 y el área
de pasaje se estima en 24 m2.
13.1) PERSONAL DOCENTE YA EXISTENTE ASIGNADO AL PROYECTO.
| GRADO | DEDICACION HORARIA SEMANAL | % DEDICADO AL PROYECTO |
| 4 | 40 | 50 |
| 3 | 6 | 100 |
| 2 | 6 | 100 |
| 3 | 40 | 50 |
13.2) PERSONAL NO DOCENTE YA EXISTENTE ASIGNADO AL PROYECTO.No corresponde
13.3) EXTENSIONES DE CARGOS DOCENTES SOLICITADAS.
| GRADO | DEDICACION ACTUAL | DEDICACION A LA QUE ASPIRA | MONTO (U$S) ANUAL * |
| 2 | 6 | 25 | 4.210 |
SUB-TOTAL U$S 4.210 (18 meses: 6315 )13.4) EXTENSIONES DE CARGOS NO DOCENTES SOLICITADAS.
- VER FORMA DE CÁLCULO EN EL INSTRUCTIVO.
No corresponde
13.5) CREACIÓN DE CARGOS DOCENTES SOLICITADA.
| GRADO | DEDICACION HORARIA SEMANAL | MONTO (U$S) ANUAL * |
| 1 | 30 | 5.005 |
SUB-TOTAL U$S 5.005 (18 meses: 7.508)
14.1) MATERIALES YA EXISTENTES.
| CANTIDAD | DESCRIPCION | INSTITUCION
QUE
LO APORTA |
VALOR ESTIMADO U$S _________________14.2) MATERIALES SOLICITADOS.
| CANTIDAD
|
DESCRIPCION | PRECIO (U$S) UNITARIO | PRECIO (U$S) TOTAL |
| Global | Material fungible ( fotocopias, transparencias, diskettes, etc. ) | 392 |
SUB-TOTAL U$S _____392_______________
14.3) OTROS GASTOS. NO SE FINANCIARAN ACTIVIDADES QUE ESTEN CONTEMPLADAS EN LOS PROGRAMAS IMPLEMENTADOS POR LA UNIDAD DE RECURSOS HUMANOS DE LA C.S.I.C. (*)
| CONCEPTO | FONDOS DE LA C.S.I.C. U$S | OTROS FONDOS U$S |
(*) Como por ejemplo: Publicaciones, Asistencias a Congresos, etc.SUB-TOTAL U$S ____________________
JUSTIFICACIÓN DETALLADA DE LOS GASTOS:
______________________________________________________________________________________
______________________________________________________________________________________
______________________________________________________
15.1) EQUIPOS YA EXISTENTES A SER UTILIZADOS EN EL PROYECTO:
DESCRIBIR Y CUANTIFICAR LOS EQUIPOS QUE SE USARAN. INDICANDO EN ESTE CASO QUIEN HARA EL APORTE (SERVICIO, OTRA INSTITUCION, ETC.)
| CANT | DESCRIPCION
|
INSTITUCION QUE LO APORTA |
| 1 | estación de trabajo (ET) de altas prestaciones del tipo multiprocesador SMP (Shared Memory Processors) con 4 procesadores, equipadas con disco SCSI, CD-ROM, unidad de cinta de alta capacidad, conexión a red FDDI de 100 mbit por segundo | Centro de Cálculo, adquirido en el proyecto ITDC de la Unión Europea |
| 2 | ET DEC-ALPHA de altas prestaciones equipadas con conexión a red Ethernet de 10 mbit por segundo | Centro de Cálculo, adquirido en el proyecto CONICYT/BID 180/92 |
| 2 | ET SUN de altas prestaciones equipadas con conexión a red Ethernet de 10 mbit por segundo | Centro de Cálculo, adquirido en el proyecto CONICYT/BID 180/92 |
| 3 | ET de altas prestaciones equipadas con disco SCSI, CD-ROM, unidad de cinta de alta capacidad, conexión a red FDDI de 100 mbit por segundo | Centro de Cálculo, adquirido en el proyecto ITDC de la Unión Europea |
| 1 | Router con interfaces: a.- WAN para conexión a Internet a 64 kb/s o más, b.- LAN ethernet para conexión a la red de Facultad de Ingeniería (fing.edu.uy), c.- LAN FDDI para conexión a las ES de la nueva red de fibra óptica (red fddi.fing.edu.uy) | Centro de Cálculo, adquirido en el proyecto ITDC de la Unión Europea |
| 10 | Software: 10 licencias por equipo del sistemas operativo AIX, 6 licencias de los compiladores C y Fortran, utilitarios: Wabi, Performance Toolbox, Distributed Smit. | Centro de Cálculo, adquirido en el proyecto ITDC de la Union Europea |
VALOR ESTIMADO U$S 200.000___________15.2) EQUIPOS SOLICITADOS: DESCRIBIR Y CUANTIFICAR LOS EQUIPOS QUE SOLICITA A LA C.S.I.C. PARA REALIZAR EL PRESENTE PROYECTO.
| CANTIDAD | DESCRIPCION | PRECIO (U$S)
UNITARIO |
PRECIO (U$S)TOTAL |
SUB-TOTAL U$S ________________15.3) BIBLOGRAFÍA SOLICITADA.
(Especifíque tipo de publicación, costo unitario, cantidad y total solicitado).-Time Series: Theory and Methods, Brockwell & Davis - Springer Verlag: U$ 100 (estim.)
ARCH: Selected Readings, Engle, Robert F. - Oxford Press: U$ 100 (estim. )
Introduction of Variance estimation: Wolter - Springer Verlag: U$ 150 (estim.)
Neural Networks: Algoritms, apps. & prog. techs. - Addison-Wesley: U$ 100 (estim.)
Eng. Apps. of Artificial Neural Networks - Bulsari & Kallio: U$ 150 (estim.)SUB-TOTAL U$S : _________785______
| SUELDOS (U$S) | GASTOS | INVERSIONES | TOTAL | |
| 1er. Año | 9.215 | 785 | U$S 10.000 | |
| 2do.Año
(6 meses) |
4.608 | 392 | U$S 5.000 | |
| TOTAL | 13.823 | 392 | 785 | U$S 15.000 |
CONSTANCIA:
SELLO
FIRMA DEL RECEPTOR DEL SERVICIO
DEL
DEL PROYECTO: ___________________
SERVICIO:
FIRMA DEL CONTADOR:____________________
FIRMA DEL SOLICITANTE:__________________________
FIRMA DEL TUTOR (En caso de Iniciación):__________________________
FECHA DE PRESENTACION ANTE LA C.S.I.C.
:
_____ /_____ /_____