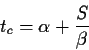One critical consideration when programming any message passing application is the task granularity. This is typically measured as the ratio of the number of bytes received by a task to the number of floating point operations the task performs.
In turn, the time needed for a message of size S to reach
destination depends on two parameters: bandwidth throughput (![]() )
and communication latency (
)
and communication latency (![]() )
(equation B.3). Thus
large messages will need more time to travel. Usually, and mostly in
``parallel-virtual-machine'', latency is so large that programs need to
communicate as little as possible in order to be efficient.
)
(equation B.3). Thus
large messages will need more time to travel. Usually, and mostly in
``parallel-virtual-machine'', latency is so large that programs need to
communicate as little as possible in order to be efficient.
The same application could be subdivided into either in high number of smaller or, alternatively, in small number of larger pieces of code. The smaller the pieces, the more communications will be between them. The relation between the amount of work in a node and the information it needs to receive in order to do that work defines the granularity of the tasks.
By doing some simple calculations of the computational speed of the workstations in the virtual machine and the available network bandwidth between the workstations, one can get a rough lower bound of the task granularity that should look for the application. The tradeoff is as follows: the larger the granularity the higher the speedup, but often with a reduction in the achievable parallelism as well. A serial code as the highest achievable granularity, it doesn't use communication, every time it is computing, but the parallelism is non-existent.
However, when working with workstation clusters with a rather high communications latency, one should prefer high granularity applications; if not, most of the time will be spent in communication among tasks through low speed channels and the overall application performance will be bad.