Desde los comienzos de la era de las computadoras, el requerimiento
de mayor poder de cálculo ha sido una constante. La Facultad de
Ingeniería no ha sido ajena a esa tendencia, teniendo actualmente
en las áreas de hidrodinámica, optimización y meteorología
un buen ejemplo de ello. Actualmente se está dando en el mundo una
preeminencia cada vez mayor de los modelos numéricos sustituyendo
donde es posible a los modelos físicos.
Por ello, y debido a la creciente magnitud de los problemas encarados
(modelación tridimensional, mallas con miles de puntos, mayor orden
de las soluciones, modelación de los fenómenos turbulentos,
interfases gráficas en tiempo real, simulación de eventos)
la capacidad computacional requerida se ha incrementado. Para satisfacerla,
además de mejorar los procesadores, se desarrolló una tecnología
basada en el uso simultáneo de más de un procesador, esquema
conceptual adaptable en buena parte a la mayoría de las aplicaciones.
Así, la paralelización de programas ha venido realizándose
en ambientes científicos y técnicos empleando supercomputadoras
con varios procesadores [DAVI90] o redes de computadoras del tipo estaciones
de trabajo (ET en lo que sigue) conectadas en red y utilizando comunicación
mediante pasaje de mensajes entre los programas ([BERG93]; [DONG93]; [KAPL96]).
Para maximizar el rendimiento de una red formada por ET interconectadas,
se hace necesario estudiar las características de uso de cada una
de las componentes de la red, de forma de poder explotar los tiempos muertos
de unas, para dejar más libres a las otras [MUTK92]. Así
se lograría un buen balance de cargas sobre la red, lo cual constituye
el objetivo final del proyecto.
El despacho de tareas o procesos sobre un conjunto no acotado de computadoras
interconectadas en red teniendo en cuenta la variable "tiempos de comunicación"
es un problema NP completo [YANG91]. Aunque en la práctica el número
de computadoras en la red está acotado, éste puede llegar
a ser muy grande, por lo que el resultado anterior da una idea de la complejidad
del problema planteado.
Por otra parte, un ambiente de este tipo visto como una unidad computacional,
tiene una capacidad de cálculo del orden de otros equipos mucho
más sofisticados (tipo mainframes o máquinas masivamente
paralelas), las cuales tienen la desventaja adicional de ser absolutamente
propietarias, poco amigables, y no sirven como puestos de trabajo individual.
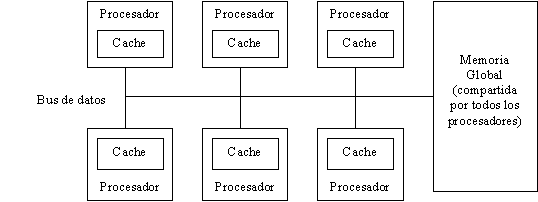
Existen estudios de balance de cargas en multiprocesadores con memoria
compartida [SUBR94], arquitectura similar al multiprocesador del CeCal,
obteniéndose buenos resultados.
Según la ley de Grosch, que se ha venido comprobando empíricamente
durante muchas generaciones de computadoras, el desempeño de una
computadora crece con el cuadrado de su valor [MENA93]. Si la computadora
forma parte de una red, ese crecimiento puede llegar a ser más que
potencial, y por tanto prohibitivo.
Por dicha razón, las estaciones de trabajo de uso personal conectadas
en red y con la posibilidad de compartir recursos conforman un ambiente
de trabajo cada vez más difundido, no sólo dentro de las
Universidades sino también en Instituciones estatales y privadas.
Sin embargo, se requiere de una administración eficiente, de forma
de habilitar los mecanismos que permitan compartir recursos, minimizando
toda perturbación en el desempeño de cada componente de la
red.
Lamentablemente, no es fácil encontrar esa administración
eficiente.
Empíricamente, se ha comprobado que la aplicación de algoritmos
sencillos de balance de cargas mejora el desempeño de los programas
distribuidos y, en general, de la red en la que son ejecutados ([SHIV92],
[WANG85]).
Mediante un buen conocimiento de los factores de uso de cada una de
las ET individuales, se podrán desarrollar algoritmos de predicción
de carga de las computadoras que conforman la red, de modo de optimizar
el desempeño de la red por medio de una mejora en el gerenciamiento
de tareas.
Algunos trabajos ya realizados con ese objetivo, han identificado los
parámetros más representativos para medir la carga de una
computadora [KUNZ91] a los que se les ha aplicado Teoría de Colas
y simulación ([AHMA91]; [EAGE86]) obteniéndose modelos sobre
los cuales comenzar un proceso de calibración de parámetros,
de forma de ajustarlos lo mejor posible a diferentes redes.
Se han utilizado también técnicas de economía,
asignando en tiempo real un costo a cada máquina componente de la
red, costo que es función de la disponibilidad de recursos libres
que tiene; los criterios de balance de cargas intentarán minimizar
el gasto, asignando más tareas a las máquinas más
baratas [WALD92]. Sin embargo, no se tiene conocimiento de implementaciones
concretas de dichos modelos para ninguna red de computadoras.
Dependiendo de las operaciones a realizar luego de detectado un desbalance
de cargas (migración de procesos, re-priorización, recolección
de información para próximas tareas son alternativas usuales),
es que se plantean diversos objetivos en función de el desempeño
que se pretende lograr de la red. [KRUE87]
Normalmente, los usuarios que comprenden que este tipo de redes tiene
una gran capacidad de cálculo ocioso y quieren aprovecharlo, subestiman
el trabajo subyacente que hay que realizar para que su programa (que actualmente
corre en un PC o en un mainframe, requiriendo días de cálculo)
pueda ser ejecutado en esta nueva arquitectura, logrando bajar así
los tiempos de procesamiento en forma muy sustancial (por lo menos, eso
es lo que le prometieron...). Los tres principales motivos por los cuales
los usuarios que necesitan grandes capacidades de cálculo no usan
este tipo de arquitectura, son (basado en [COOK94]):
1) que no hay beneficios reales en aplicaciones reales:
las mejoras de desempeño que teóricamente se podrían
lograr
mediante la paralelización
de código, se ven enfrentados a problemas tales como deficiencias
en la configuración de las
redes (lo cual las hace inevitablemente ineficientes),
hardware poco confiable, etc.
2) falsas promesas respecto a la facilidad de programación.
Hay una gran falta de herramientas de uso común para el desarrollo
de aplicaciones paralelas (debuggers, profilers,
ambientes de desarrollo, etc.)
3) los sistemas no funcionan bien; las pocas herramientas
que existen, o son de dominio público (lo cual les da la ventaja
de
disponerse de los fuentes, en caso de problemas,
pero con la desventaja de tener soporte nulo o mínimo) o son productos
comerciales extremadamente caros.
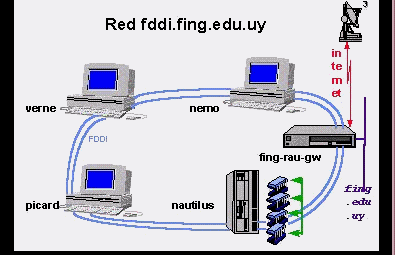
Afortunadamente, en la Facultad de Ingeniería la realidad no
es tan pesimista: disponemos de una red de más de 100 poderosas
estaciones de trabajo conectadas en red, redes de fibra óptica operando
a 100 Mbit por segundo, un multiprocesador, todo funcionando en forma armónica,
estable y performante, debido a la correcta administración de la
misma. Por otro lado, el Centro de Cálculo dicta todos los años
(a través de docentes involucrados en este mismo proyecto) un curso
de extensión orientado a docentes y no docentes internos y externos
a la facultad (Cálculo Intensivo en Sistemas Distribuidos en
una Red de Computadoras), de forma de introducir a una asistencia multidisciplinaria
y no necesariamente informática, cuáles son las facilidades
que este tipo de arquitecturas les pueden proveer.
Hoy en día, en la Facultad de Ingeniería se ejecutan programas
paralelos (corriendo en forma distribuida en la red) desarrollados en esa
misma casa de estudios por investigadores de variados institutos (Centro
de Cálculo, Inst. de Mecánica de los Fluidos, Inst. de Matemáticas,
Inst. de Computación). Estos mismos han sido utilizados como banco
de pruebas para evaluar los nuevos despachadores de tareas que se implementaron
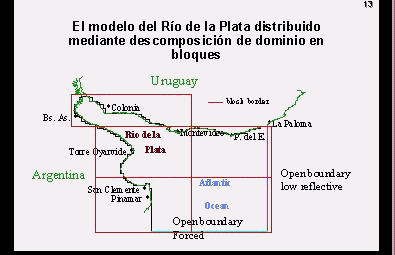
durante el proyecto. A modo de ejemplo se utilizó un modelo numérico
de corrientes de marea y viento del Río de la Plata, tema de estudio
por investigadores de este grupo ([GUAR92]; [KAPL92]; [KAPL96]). El modelo
incorpora la paralelización vía descomposición del
dominio de cálculo en bloques [GROP90]. Esto posibilita mejorar
la solución del problema al trabajar con mallas de mayor densidad
en el modelo global y emplear modelos encajados, con bloques del dominio
con tamaño de grilla menor que en el modelo global (del orden de
100 m) para zonas de interés. Una de las aplicaciones más
destacadas es la modelación de corrientes en zonas costeras, para
estudios del impacto ambiental del vertido de contaminantes o de eventuales
derrames de hidrocarburos. Una característica propia del problema
es la necesidad de modelar globalmente todo el Río de la Plata para
obtener las condiciones de borde a aplicar en el modelo encajado que incluye
a la zona de interés.
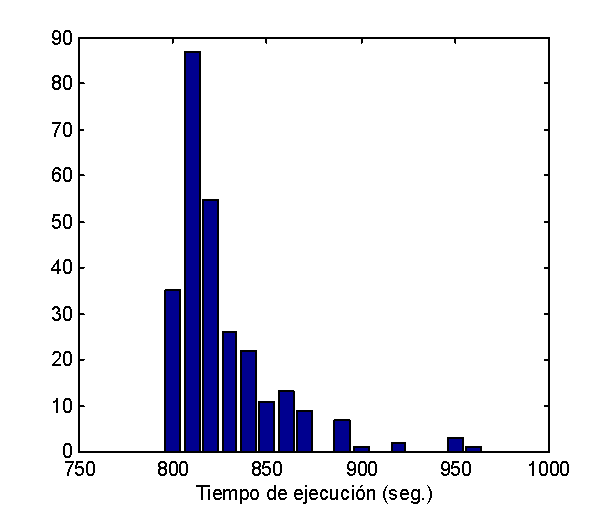
Dicho programa ya viene siendo probado: modelando en una grilla de 640.000
celdas el tiempo de cálculo del programa serial (utilizando una
única estación de trabajo) para 24 horas de simulación
resulta ser de 7h30 en tanto el tiempo empleado por el programa usando
4 ET es de 2h20 resultando en una aceleración del cálculo
de 3,2 veces. En tanto que modelando simultáneamente las corrientes
y el Transporte y Dispersión de un contaminante la
aceleración
del cálculo llega a 3,5 (tiempo 1 ET 15h, tiempo 4 ET 4h15).
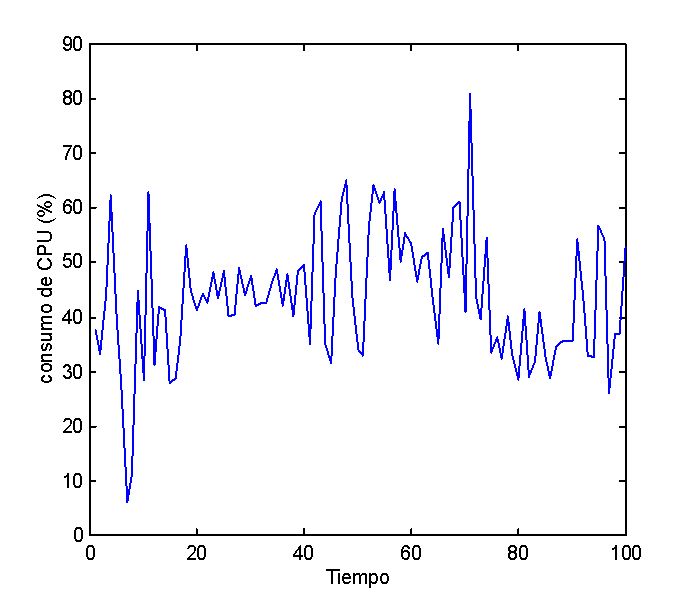
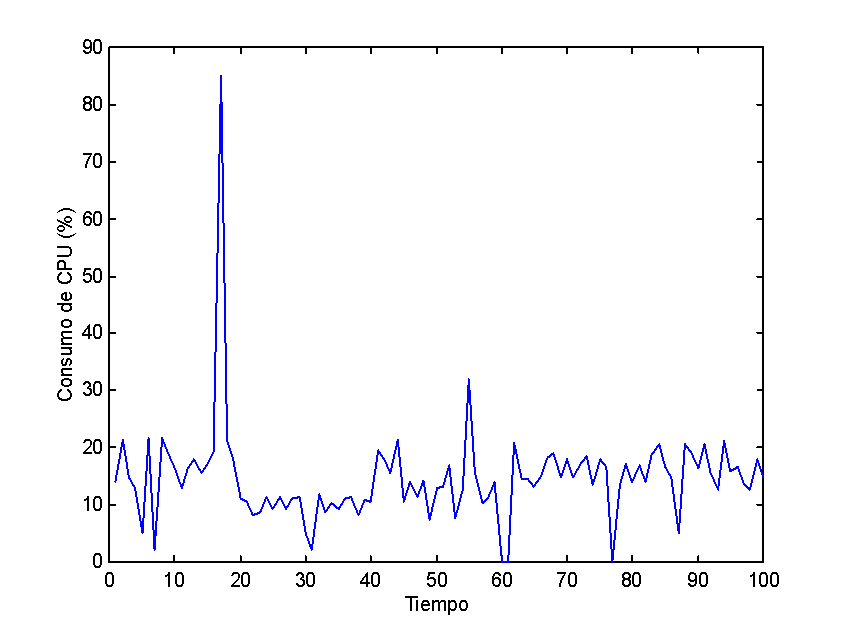
Es de tener en cuenta que estos tiempos fueron obtenidos empleando las
ET en modo dedicado exclusivamente al modelo. Se ha visto que los tiempos
de cálculo, empleando las ET en modo
no dedicado, pueden
llegar a incrementarse hasta el orden del tiempo serial, dependiendo de
las tareas que se ejecuten en ese momento. La meta del presente proyecto
es la de minimizar este incremento optando por las ET adecuadas en cada
momento.
Todos estos requisitos plantean formidables demandas en capacidad de
cálculo a la computadora utilizada. La única solución
práctica ha sido la utilización de PVM [GEIS93] puesta en
práctica ya en el CeCal [KAPL96]. Existe por lo tanto buen conocimiento
de las prestaciones de la red presente en una aplicación concreta
de interés para el país.
El proyecto que se informa forma parte de una estrategia de desarrollo
para disponer en nuestra Facultad de un sistema capaz de atender las necesidades
de cálculo intensivo de las aplicaciones de ingeniería que
el medio demanda. Como ejemplos, el cálculo de la evolución
de una mancha de petróleo en el Río de la Plata o la simulación
del clima en el Uruguay son tareas que demandan fuertemente a las computadoras
utilizadas.
La solución más simple sería el uso de un supercomputador.
En nuestro caso esta alternativa se descarta directamente por su costo
prohibitivo. Una segunda alternativa sería utilizar las técnicas
de cálculo distribuido entre varias computadoras tipo estaciones
de trabajo (ET) exclusivamente dedicadas a tal fin. En este caso
se puede utilizar software apropiado para lograr valores de desempeño
comparables a la del supercomputador. Sin embargo, esta alternativa también
es inviable en nuestro medio, por lo que la única posibilidad con
un costo razonable es utilizar una red de ET no exclusivamente dedicadas,
compartiendo así su uso con otras aplicaciones. Esta alternativa
mejora sustancialmente la relación costo/beneficio del equipamiento,
al no requerir una dedicación exclusiva del mismo al cálculo.
La situación puede ser distinta en los países desarrollados,
donde tanto la primera como la segunda alternativa son moneda corriente.
Es por ello que el software desarrollado para manejar redes de ET presta
poca atención al problema de la carga futura de la máquina.
Simplemente despachan las tareas a medida que se les solicita asignándoselas
a las CPUs que no están siendo ocupadas (en el caso de las redes
dedicadas) o a la menos cargada instantáneamente (en el caso de
redes de uso compartido).
El problema que se plantea en este proyecto es lograr un buen balance
de cargas de una red de ET, a través del mejor gerenciamiento del
despacho de tareas.
Esta mejora se lograría estudiando los patrones de carga de las
computadoras componentes de la red considerada, tratando de predecir su
comportamiento futuro y, sobre la base de ello, tomar una decisión
óptima en el despacho de tareas (con un horizonte del orden de minutos).
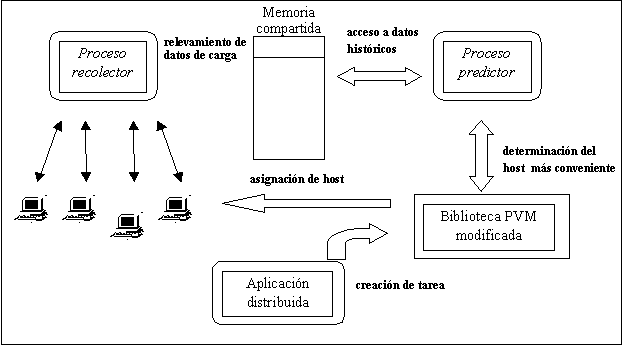
Cada vez que una aplicación distribuida tiene que lanzar la ejecución
de un proceso a la red, no debe solamente tener en cuenta la carga instantánea
de las computadoras interconectadas, sino que también debe ser considerada
la información de carga esperada de los componentes de la red.
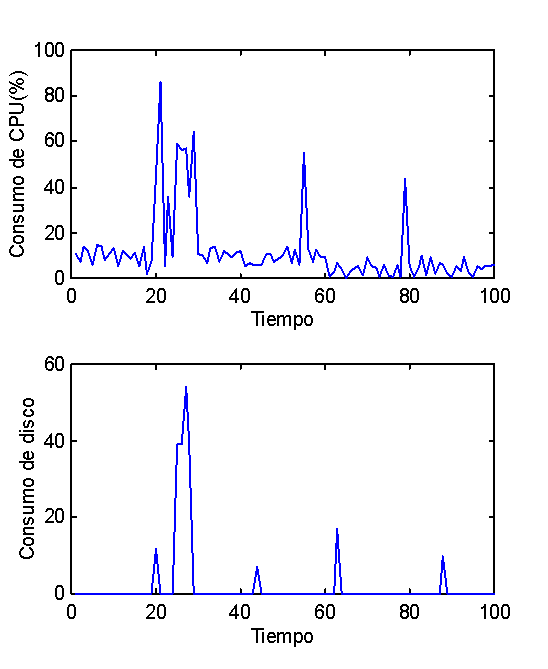
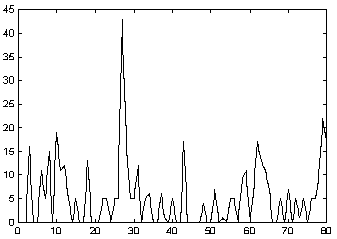
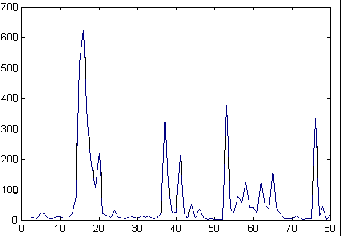
Para y previo a ello, fue necesario obtener información histórica
de la red, a la que se le intentaría ajustar modelos, hasta llegar
a un modelo predictor satisfactorio. Esto ya fue realizado con series temporales
de tipo meteorológico en otros proyectos del CeCal [LOPE97b], con
resultados igualmente exitosos. La modelación de los datos históricos
de carga consiste en uno de los principales objetivos del proyecto.
Los nuevos mecanismos de despacho de tareas debían ser integrados
al sistema PVM (Parallel Virtual Machine) ([GEIS93]; [DONG93]), que es
uno de los más usados para programar aplicaciones distribuidas en
una red de computadoras. Se requería que la integración de
estos nuevos algoritmos de despacho fuese totalmente transparente para
los usuarios que ya tengan aplicaciones PVM en funcionamiento. Los usuarios
deberían ser capaces de aprovechar las ventajas de los nuevos algoritmos
de despacho sin cambios en el código de los programas, simplemente
compilando sus aplicaciones contra el sistema PVM modificado que se desarrollaría
en este proyecto.
Finalmente, para probar la bondad de los nuevos algoritmos considerados,
es necesario confrontarlos con las estrategias nativas de PVM, bajo las
mismas condiciones de carga. Esto implicó el diseño de un
experimento que permite correr programas distribuidos bajo condiciones
de carga prefijadas (o sea, no libradas al azar), pero usando distintos
criterios de predicción de carga a futuro.
Lograr este ambiente no es un problema menor y consistió en otro
de los objetivos del proyecto. Para ello, se dispuso de una serie histórica
de la carga de las computadoras de la red en estudio, y datos fehacientes
de su potencia relativa. Se requirió implementar programas que permiten
reproducir la situación de carga de esas computadoras en forma lo
más "coherente" posible con la información histórica
disponible puesto que era necesario poder repetir el experimento de lanzar
un mismo programa distribuido, a un mismo estado de carga de la red, con
distintos criterios de predicción, de forma de establecer una justa
comparación.
El programa diseñado, denominado "Replicador de Cargas" permite
replicar datos históricos de carga sobre un conjunto de máquinas
con valores bajos de carga base. Solamente contando con un ambiente con
exactamente las mismas condiciones de carga será posible realizar
una comparación válida entre las nuevas estrategias de despacho
y la ya existente en PVM.
El desempeño del sistema en su conjunto fue evaluado utilizando
programas de cálculo científico actualmente operativos en
el CeCal, relacionados con aplicaciones reales de interés para el
Uruguay. En particular se empleó el mencionado programa PTIDAL
para el cálculo de corrientes de marea desarrollado en el CeCal
[KAPL96]. Continuando con el ejemplo ofrecido, para analizar el comportamiento
de una mancha de petróleo (como la del recordado accidente del buque
San Jorge ocurrido en 1998) es necesario simular una semana de corrientes
y del transporte del contaminante. Dicho cálculo realizado en forma
serial (operando en una única ET potente y dedicada) emplearía
4,5
días, lo cual resulta inaceptable. Para decidir las medidas
a tomar que contrarresten los efectos catastróficos del accidente
los plazos son mucho más exigentes.
En cambio el programa distribuido empleando 4 ET (también dedicadas
exclusivamente) simula dicho comportamiento en sólo 1,2 días,
lo
cual sería aceptable si fuera posible disponer dicho equipamiento
en forma exclusiva. El problema surge al realizar la simulación
en forma distribuida con las ET no dedicadas exclusivamente a este
cálculo lo que ocasiona un incremento del tiempo de cálculo
que puede a llegar a superar el tiempo serial en función
de cómo se seleccionan las ET a emplear. La meta final del presente
proyecto consistió en optimizar el uso de las ET de forma de poder
realizar el cálculo antedicho minimizando el tiempo de cálculo.




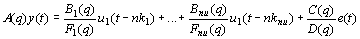 (3)
(3)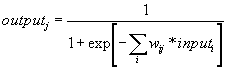
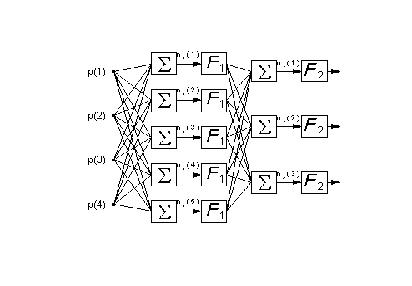
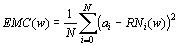
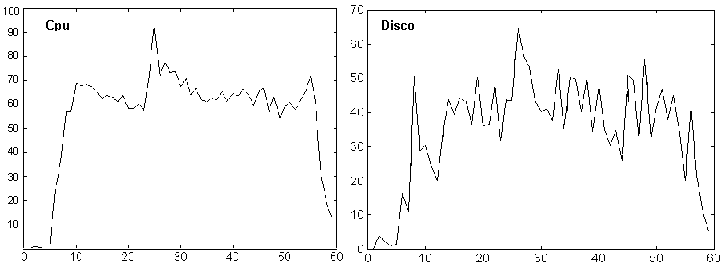
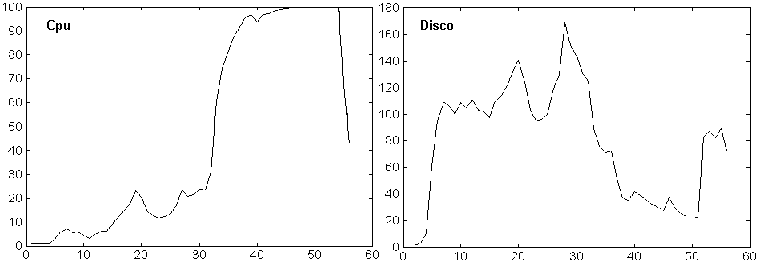
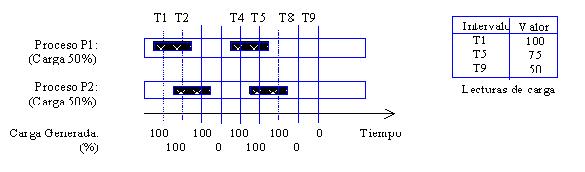
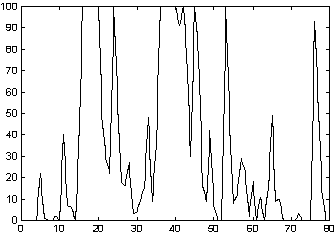
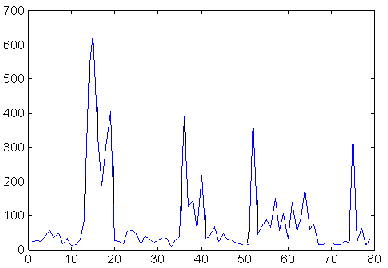
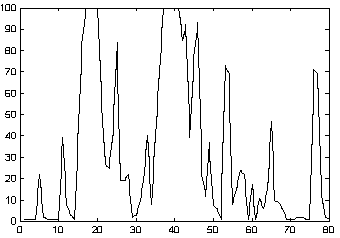

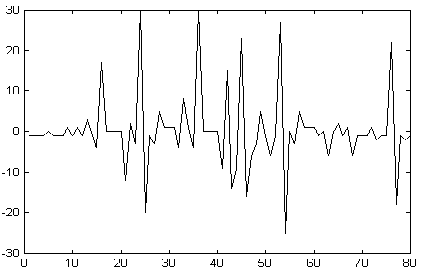
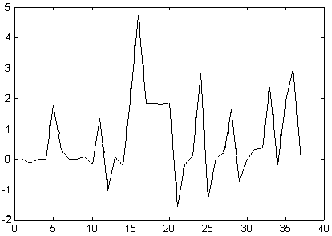
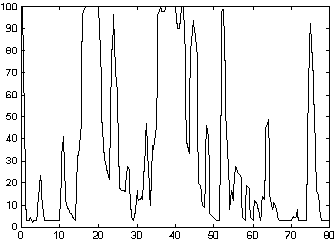
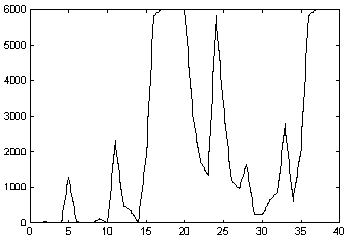
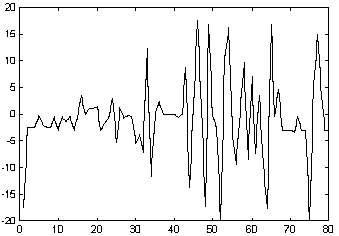
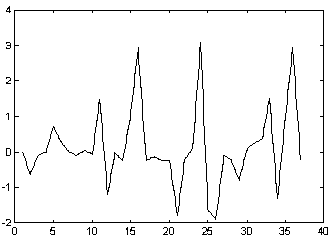
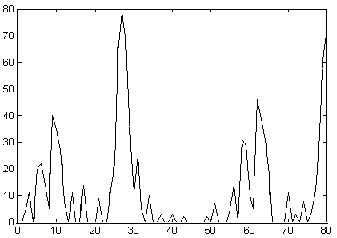

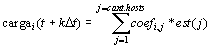 . Los coeficientes
coefi,jse
calculan aplicando Mínimos Cuadrados de modo de ajustar los valores
a una función lineal.
. Los coeficientes
coefi,jse
calculan aplicando Mínimos Cuadrados de modo de ajustar los valores
a una función lineal.